- Publicado el
Legacy Code ile Boğuşurken Hayatta Kalma Rehberi 🚀
- Autor

- Autor
- Batuhan Onder
Contents
- Legacy Code İle Boğuşurken Hayatta Kalma Rehberi 🚀
- Legacy kod nedir? Neden bizleri zorlar?
- Legacy Kodla Yüzleştiğinde Yapman Gerekenler
- Gözlem ve Keşif Süreci
- Değişiklikliği Tanımlamak
- Test Noktalarını Belirlemek:
- Bağımlılıkları Kırmak
- Test Double Tipleri
- 1- Dummy Objects
- 2- Fake Objects
- 3- Stubs
- 4- Spies
- 5- Mocks
- Kodunla Barış İçinde Yaşamak İçin: Test Yaz!
- Değişiklik Zamanı!

Legacy Code İle Boğuşurken Hayatta Kalma Rehberi 🚀
Hadi itiraf edelim, hepimiz en az bir kere içinde ne olup bittiğini anlamadığımız, dokununca bir şeyler ters gidecek gibi hissettiren bir kod yığını ile karşılaştık. Test yok, dokümantasyon hak getire, metotlar ise sözleşmedeki ara sayfalar gibi.. O sıra hepimizin ağzından “Abi bu kodu kim yazmış ya” çıkmıştır. Tabii ki; gelecekteki bizler için de aynı geleceği hazırladığımızı unutuyoruz 🥲
Evham yapmayalım. Bu yazıda, testsiz legacy kodlara nasıl güvenli şekilde refactor yapabileceğini, bağımlılıkları nasıl kırabileceğini ve “Bunu değiştirdim ama umarım patlamaz” stresinden nasıl kurtulabileceğini konuşacağız. Hazırsan başlayalım.
Legacy kod nedir? Neden bizleri zorlar?
Sektörde aşina olduğumuz bir terimdir. Genellikle kötü, anlaşılmaz, eski ve artık desteklenmeyen eski teknolojileri kullanan, değiştirmesi zor veya kodun geliştiricilerinden kimselerin kalmadığı veya devralınan kodlar için Legacy Kod tabirini kullanırız. Tabi bu tabir doğru olsa da Michael C. Feathers’ın Working Effectively with Legacy Code kod kitabında çok güzel bir tanım var. O da şudur ki, “Testsiz kod kötü koddur.”. Bir kodun kötü olması için üzerinden bir zaman geçmesi gerekmez veya anlaşılır kod bile kötü kod olabilir. Hatta şu anda hangi proje ile ilgileniyorsanız o bile.
Test olmayan bir yerdeki geliştirme aslında doğrulanabilir değildir. Bu nedenle değişikliklerin sonuçlarını tahmin edemeyiz. Özellikle de büyük context’ e sahip projelerde bu körlük başa bela demektir. Hadi bunu basitçe kanıtlayalım:
func getRecordIds() []int {
recordIds := []int{5, 3, 9, 1}
sort.Ints(recordIds)
return recordIds
}
func printRecordIds() {
fmt.Println("Records: ", getRecordIds())
}
Yukarıdaki koda iyi niyetli yaklaşırsak, sorting işlemini gereksiz olduğunu çok net görüyoruz. Hemen onu oradan kaldırıyoruz.
func getRecordIds() []int {
recordIds := []int{5, 3, 9, 1}
return recordIds
}
func printRecordIds() {
fmt.Println("Records :", getRecordIds())
}
Ne kadar güzel oldu değil mi? Boşa bir sıralama yapmıyoruz.Boşa kaynak kullanmıyoruz. Boşa kod kalabalığı yok. Hemen kodu çalıştırdık ve record’ ların geldiğini gördük ve deployumuzu gerçekleştirdik(Acceptance ve diğer testlerimizi de yok sayalım.). Çok geçmeden şöyle bir support talebi geldi:
Merhabalar X, tablodaki ilk kaydı güncelle butonumuz. 1 nolu kaydı güncellemiyor.

Döndük koda baktık ki; button arkasında gelinen yerde şöyle bir kod parçası var:
func GetFirstRecord() int {
ids := getRecordIds()
return ids[0]
}
Başta bu kodun olduğunu söylemedin der gibisiniz. Fakat unutmamalıyız ki davranışta yapılan hatalarda IDE’ler de bizleri uyarmazlar. İyi niyetli, hızlıca alınmış bir aksiyon sonucunda çok basit olan kodumuzun dahi doğruluğunu bir anda bozabildik. Halbuki her bir metodumuz için testlerimiz olsaydı. Doğrudan davranıştaki değişiklikten etkilenecek ve bizi uyaracaktı. Umarım faydalı ve ispatlayıcı bir örnek olmuştur.
Bu nedenle, yukarıdaki tanım belki bizler için daha doğru bir tanım olacaktır. Kodumuzun kötü veya legacy olması için karmaşık ve dokunmaktan çekineceğimiz kodlar olması gerekmez. Kimi zaman basit ve değiştirirken gram endişe duymadığımız kodlar da kötü olarak nitelendirilebilir. Yani bir kodun iyi veya kötü olması için testlerimiz bu kadar mühimdir.
Legacy Kodla Yüzleştiğinde Yapman Gerekenler

Her şeyde olduğu gibi, projelerde de ilk adımlarımızı atarken aldığımız kararlar süreci daha iyi veya daha kötü hale gelmesini etkileyecektir. Kırmızı hapı alıp; bu bataklıktan kurtulmak mı? Yoksa, mavi hapı alıp; bataklıkta kalmaya devam etmek mi? Eğer ki kırmızı hapı seçerseniz; bahsedeceğim adımlarla ilerlemek pekala daha faydalı olacağını düşünüyorum.
Gözlem ve Keşif Süreci
Herhangi bir projeyi açar açmaz kod yazamayacağımız bir gerçektir. Bir değişiklik yapacaksak önce o projeyi yakından tanımamız gereklidir. Bunun için pek çok yöntem vardır. Bir projeyi incelerken genellikle kendime şu soruları sorarken buluyorum:
- Projenin amacı nedir?
- Hangi teknolojileri kullanıyor?
- Kodumuzun girdileri ve çıktılar neler?
- Çıktıyı üretirkenki kod bağımlılıkları neler?
- Testerimiz var mı?
- Herhangi bir design pattern kullanılmış mı? File architecture’ ı nasıl?
Bu 6 soru bana kalırsa bir proje hakkında hızlı bir portfolio oluşturacaktır. Çoğu zaman bu gibi projelerde dokümantasyon varsa işleri bir nebze kolaylaştırır ama bana kalırsa dokümanları güncel tutmak yazılım alanında en zor işlerden birisidir. Ve hemen hemen tüm dokümantasyonlar da atıl kalmaktadır(en azından benim için öyle 🙂). Bu nedenle, her zaman code base de gezintiye çıkmanın en doğru yol olacağını düşünüyorum. Kimi zaman proje isminden anladığımız amaç, koda girdiğimizde farklılaşabilir. Testlerin de bir dokümantasyon olduğunu biliyoruz. İyi isimlendirilmiş, davranışları çok iyi cover eden bir test; kod hakkında bilmeniz gereken her şeyi size bir tepside sunacaktır. Tabii ki, test var ise.. Eğer yok ise, zaten kaçış yoktur. Saatlerimizi bu arkadaşla paylaşmak, bir işi hemen canlıya almaktan bizim için daha faydalı olacaktır.
Değişiklikliği Tanımlamak
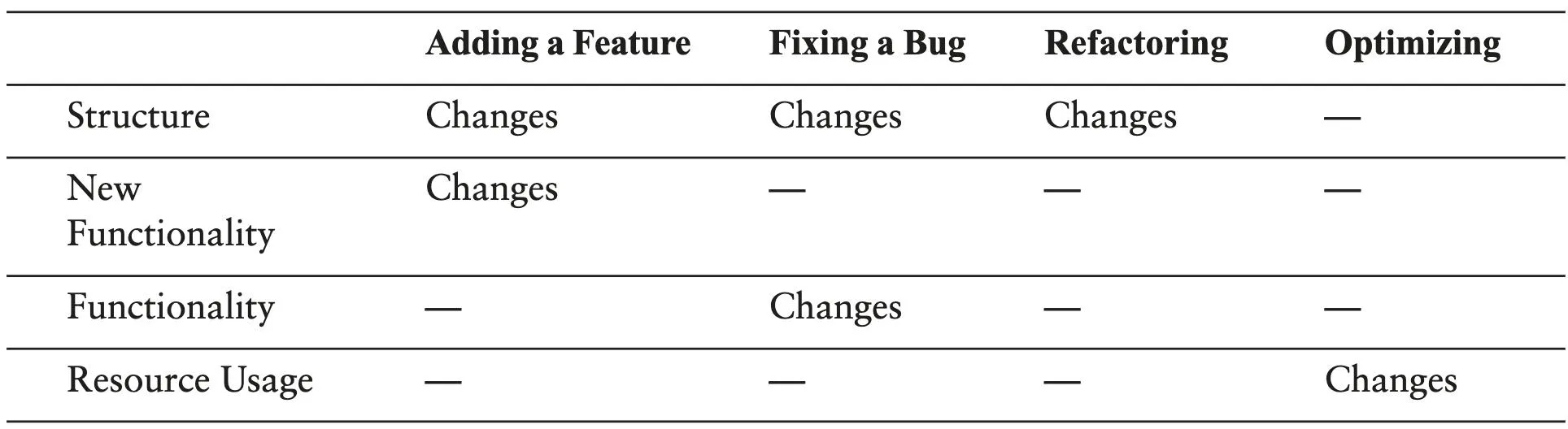
Michael Feathers yine kitapta değişiklikleri 4 madde de şöyle özetliyor:
- Adding a feature
- Bug fix
- Refactoring
- Optimizing
Bir iş aldıysak öncelikle o işte yer alan isterin, koda karşılık gelecek olan değişikliği tanımlamamız gerekiyor. Çünkü; bizlerin, değişikliği doğru şekilde anlaması aslına bakılırsa bizim koda yaklaşım patternlerimizi de etkiliyor. Atıyorum, yeni bir feature eklediğimizde kodun önceki davranışına ek olarak eklenen davranışı da yerine getirmesini bekleriz. Ama bir refactoring de kodun davranışının aynı kalmasını isteriz. İlk örneğimde yeni bir test yazmamız gerekirken; ikinci örneğimizde var olan testlerin aynı şekilde geçmesini bekleriz. Yani bizim geliştirme stratejimizi değişikliğe göre değiştirmemiz, kendimizi oto pilottan çıkarmamız gerekiyor.
Test Noktalarını Belirlemek:
Bu adımda kodun nerelerine testleri ekleyeceğimize dair keşif sürecini içeriyor. Yani test eklemek için uygun noktaları tespit etmeliyiz. Bunu söyleyince kafamızda “test ekleyemediğimiz senaryo olması mümkün mü?” diyebilirsiniz. Buradaki test olarak bahsettiğimiz testin unit test olduğunu unutmamak gerekiyor. Örneğin, aşağıdaki DB connection kuran method için doğrudan bir test yazmak pek de mümkün gözükmüyor.
func ConnectDB() (*sql.DB, error) {
db, err := sql.Open("postgres", "user=admin password=secret dbname=mydb sslmode=disable")
if err != nil {
return nil, err
}
return db, nil
}
Elbette ki burayı test etmek için integration test daha doğru olacaktır.
Test noktalarını belirlemeye gelince başlıca olarak kodun hangi kısmında değişiklik yapacaksak o değişikliğin etrafındaki noktaları belirlenmelidir. Ardından burası için test var mı sorusu geliyor. Eğer ki kod için testler varsa bunları kullanabilecek mıyız yoksa yeni test mi eklememiz gerekiyor buna bakmalıyız. Son olarak hangi input ve outputları test edeceğimizi belirleriz. Yani, bir fonksiyon veya metot çağrıldığında hangi verileri alıyor, nasıl sonuçlar üretiyor bunu belirlemelisiniz.
Örneğin elimizde şöyle bir metot olsun ve indirime sabit bir kargo fiyatını dahil etmeyecek şekilde güncellemek isteyelim:
func CalculateDiscount(totalAmount float64, discountRate float64) float64 {
if totalAmount <= 0 || discountRate < 0 || discountRate > 100 {
return 0
}
return totalAmount * (1 - discountRate/100)
}
Değişiklik Yapılacak Alanı Tespit Etme: Return ettiğimiz yerde total amount’tan kargo ücretini çıkaracağız.
Test Mevcut mu?: İlk olarak, metot için var olan bir test var mı diye kontrol etmeliyiz. Evet, var diyelim. Bu testlerin fonksiyonun tüm sınırlarını (edge cases) test edip etmediğine bakmalıyız.
Input ve Output belirleme: totalAmount, discountRate değerleri inputumuz. Return’deki işlem sonucumuzda bizim outputlarımız.
Bağımlılıkları Kırmak
Belki de, şu ana kadar geldiğimiz kısımda en zor olan bölüm burası olacaktır. Değişikliklerimizi biliyoruz, sistemi nasıl test edeceğimize karar verdik. Tamamen sistematik geldiğimiz bu ideal koşullarda gerçekliğe dönmek gerekirse; bir sınıfın bağımsız tek başına işlem yaptığı nadir senaryolardan biri olacaktır.
Genellikle sınıflarımız bir başka sınıfa bağımlı halde işlemleri yürütür. Aslına bakılırsa bu işin doğasında vardır. SOLID uyguladığımız senaryoda zaten bir sınıf yapması gereken işleri yapar, işi olmayan operasyonları ise bu işi üstlenen diğer sınıflara bırakır. Bu konuda Akın Kaldıroğlu hocamızdan duyduğum “Efradını cami, ağyarını mani.” osmanlıca deyimi oldukça güzel bir şekilde bu durumu özetler nitelikte. Efradını cami; kapsaması gereken her şeyi kapsayan, ağyarını mani ise; içermemesi gereken hiçbir şeyi içermeyen anlamına gelir. Örnek vermek gerekirse;
"Kuş, uçabilen hayvandır." (Bu genelleme yanlışlık taşır. Çünkü tavuk, penguen ve devekuşu gibi uçamayan kuşlar da var.)
"Kuş, omurgalı, sıcakkanlı ve tüyleri olan yumurtlayan hayvandır." (Bu genellemede ise tüm kuş türünün ortak noktalarını daha spesifik şekilde ortaya çıkarıyor.)
Bu mantıkta, zaten bizim servislerimiz de kapsaması gereken işi yapmalıdır. Kapsamaması gereken işleri bağımlı olduğu diğer sınıflarda gerçekleştirmelidir veya bu sorumluluğu hiç üstlenmemelidir. Biraz SOLID ve Clean Code konularına girmiş olsam da bu bilgi ışığında, bu durumun sürekli karşımıza çıkabilir olduğunu hatırlatmak istedim.
Testlerimizi yazarken; test edeceğimiz sistemi bağımlı olduğu diğer sistemlerden yalıtmamız gerekir. Eğer ki bu yalıtma işlemini yapmazsak daha büyük bir sistemi test etmiş oluruz. Hangi sistemi test etmek istiyorsak o sistemi izole edeceğiz. Bu kapsamda, şu çıkarımı yapmak pekala uygundur: unit testler, sınıflara yazılır; o zaman sınıfı diğer bağımlılıklarında yalıtmamız gerekiyor. Bağımlılıkları kırmak için de Test double’ ları kullanıyoruz.
Test double terimi, aslına bakarsanız Gerard Meszaros’un xUnit Test Patterns kitabı üzerinde çalışırken çıkıyor. Fakat, Martin Fowler abimiz galiba terimi çok sevecek oluyor ki, kitap çıkmadan hemen camiaya test doubleları anlattığı ufak yazıyla duyuruyor. İşin gerçeğini söylemek gerekirse; ben de bu terimi ilk olarak Martin abimizden duymuştum. Makaleyi yazarken referans almak adına tekrardan test double yazısına bakayım dedim. Orada bu detayı atladığımı farkettim. Bu da öyle bir bilgi işte 😁. Çok uzatmadan gelin Test Double’ lara bir göz atalım.
Test Double Tipleri
1- Dummy Objects
Dummy object’ ler etrafta dolaştırılır ancak asla kullanılmazlar. Genellikle, sadece parametre listelerini doldurmak için kullanılırlar. Şöyle ki; elimizde şu şekilde bir PaymentProcessor sınıfımız olsun.
package payment
import (
"errors"
)
var (
ErrInvalidAmount = errors.New("Invalid amount")
)
type PaymentGateway interface {
ProcessPayment(amount float64) error
}
type PaymentProcessor struct {
gateway PaymentGateway
}
func NewPaymentProcessor(gateway PaymentGateway) *PaymentProcessor {
return &PaymentProcessor{gateway: gateway}
}
func (p *PaymentProcessor) Process(amount float64) error {
if amount <= 0 {
return ErrInvalidAmount
}
return p.gateway.ProcessPayment(amount)
}
Örnekteki class içerisindeki Process metodunu test ederken gerçekten bir payment üzerinde işlem yapmak istemeyiz. Bu durumda, PaymentGateway arayüzünü implemente eden bir dummy object oluşturabiliriz. Bu dummy object, ProcessPayment metodunu içerir ancak metodun içeriğinde herhangi bir işlem yapmaz.
type DummyPaymentGateway struct{}
func (d *DummyPaymentGateway) ProcessPayment(amount float64) error {
return nil
}
func Test_process_should_return_success_with_dummy(t *testing.T) {
// Arrange
dummyGateway := &DummyPaymentGateway{}
processor := NewPaymentProcessor(dummyGateway)
// Act
err := processor.Process(100.0)
// Assert
assert.NoError(t, err, "Process should not return an error")
}
2- Fake Objects
Fake object’ler, gerçek bir bileşenin basitleştirilmiş bir versiyonudur. Fake objectler genellikle, gerçek bileşen testlerde kullanılamayacak kadar karmaşık, kullanılamaz veya pratik olmadığında kullanılır. In memory database test bunun için güzel örnektir. Burada metotlar gerçekten uygulanır ama istenen cevapları döner.
type FakePaymentGateway struct {
processedAmounts []float64
}
func (f *FakePaymentGateway) ProcessPayment(amount float64) error {
if amount <= 0 {
return errors.New("Invalid amount")
}
f.processedAmounts = append(f.processedAmounts, amount)
return nil
}
func Test_process_should_return_success_with_fake(t *testing.T) {
// Arrange
fake := &FakePaymentGateway{}
processor := NewPaymentProcessor(fake)
// Act
err := processor.Process(100.0)
// Assert
assert.NoError(t, err, "Process should not return an error")
assert.Len(t, fake.processedAmounts, 1, "Processed amounts should contain one element")
assert.Equal(t, 100.0, fake.processedAmounts[0], "Processed amount should be 100.0")
}
3- Stubs
Stub'lar test sırasında yapılan çağrılara önceden hazırlanmış cevaplar sağlar.
type StubPaymentGateway struct {
responseError error
}
func (s *StubPaymentGateway) ProcessPayment(amount float64) error {
return s.responseError
}
func Test_process_should_work_with_stub(t *testing.T) {
// Arrange
stub := &StubPaymentGateway{responseError: nil}
processor := NewPaymentProcessor(stub)
// Act
err := processor.Process(100.0)
// Assert
assert.NoError(t, err, "Process should not return an error")
}
4- Spies
Spies, nasıl çağrıldıklarına bağlı olarak bazı bilgileri de kaydeden taslaklardır.
type SpyPaymentGateway struct {
calledWithAmount float64
}
func (s *SpyPaymentGateway) ProcessPayment(amount float64) error {
s.calledWithAmount = amount
return nil
}
func Test_process_should_track_called_amount_with_spy(t *testing.T) {
// Arrange
spy := &SpyPaymentGateway{}
processor := NewPaymentProcessor(spy)
amount := 100.0
// Act
_ = processor.Process(amount)
// Assert
assert.Equal(t, amount, spy.calledWithAmount, "Expected called amount to be %v, but got %v", amount, spy.calledWithAmount)
}
5- Mocks
Mock 'lar, almaları beklenen çağrıların bir spesifikasyonunu oluşturan beklentilerle önceden programlanmıştır. Beklemedikleri bir çağrı alırlarsa bir istisna fırlatabilirler ve bekledikleri tüm çağrıları aldıklarından emin olmak için doğrulama sırasında kontrol edilirler.
type MockPaymentGateway struct {
expectedAmount float64
t *testing.T
}
func (m *MockPaymentGateway) ProcessPayment(amount float64) error {
if amount != m.expectedAmount {
m.t.Errorf("Expected amount: %v, Coming amount: %v", m.expectedAmount, amount)
}
return nil
}
func Test_process_should_call_mock_with_expected_amount(t *testing.T) {
// Arrange
expectedAmount := 100.0
mock := &MockPaymentGateway{expectedAmount: expectedAmount, t: t}
processor := NewPaymentProcessor(mock)
// Act
err := processor.Process(expectedAmount)
// Assert
assert.NoError(t, err, "Process should not return an error")
}
Kodunla Barış İçinde Yaşamak İçin: Test Yaz!

Yazılım kariyerimde bir çok projeyle kavga ettiğimi biliyorum. Başlarda gerçekten barbar bir savaşçı olduğumu itiraf etmek istiyorum. Kodu zevkle yazmak yerine; çoğu zaman kodu yaz, debug et. Kodu düzelt. Debug et. Olmadı, yeniden yaz. Debug et. Stage ortama gönder. Hayda şurayı atlamışım, düzelt. Debug et. Gönder, olmadı…. Adeta dark souls evreninde boss ile kapışıyor gibiydim. Cidden yorucuydu. Hayatının bir bölümünde de olsa, bu hataya düşen developer kardeşlerimin olduğunu biliyorum. Bu nedenle, benim için bu başlık, kesinlikle bu iş için biçilmiş kaftan.
En başta verdiğim örnekte, test yazmadan değişiklik yapınca nasıl bir felaketle karşılaşacağımızı az çok görmüştük. Şu ana kadar geldiğimiz adımlarda hala daha koda değişiklik yapmadığımızı unutmayalım.
Öncelikle testlerimizi yazmaya başladığımızda amacımızı net olarak belirlememiz gerekir. Hangi functionality’ e veya davranışa test yazıyoruz, girdilerimiz ve çıktılarımız ne olmalıdır gibi sorularımız kafamızda şekillenmiş ise testlerimiz daha odaklı olacaktır. Bu şekilde, istenilen davranışın yeterli şekilde cover edildiğinden emin olabiliriz. Bu şekilde testimizin namingleri de daha isabetli olacaktır.
Testlerimizi isimlendirirken naming patternler kullanmak projemizde standartı yakalamak ve okunabilirliği arttırıcaktır.
Testlerimizi kurgularken kompozisyon bütünlüğü için AAA pattern’ i uygularsak; elbetteki daha anlaşılır ve okunaklı testlerle sonuçlanacaktır.
- Arrange : Test için gerekli olan nesnelerin ve verilerin hazırlanması.
- Act : Test edilmek istenen işlemin gerçekleştirilmesi.
- Assert : Gerçekleşen işlemin beklenen sonuçlarla karşılaştırılması
Testlerimizi yazdıktan sonra IDE’lerin Run tests with Coverage özelliğini de kullanırsak hiç bir davranışı atlamadığımız konusunda bizlere güzel infolar verecektir.
Testlerimizin de projemizin bir parçası olduğunu kabul etmek lazım. Her nasıl codebase’ e kod yazarken temiz kodlar yazmaya çalışıyorsak, testlerimize de aynı yaklaşımla kodlar yazmalıyız.
Unutulmamalıdır ki; testler en güzel dokümantasyonlardır. Harika testler, kodumuzun yaşam süresine olumlu katkılar sağlayacaktır.
Değişiklik Zamanı!

Kendimizi emniyete aldığımıza göre artık değişikliklere veya refactoring ‘e başlayabiliriz. Fakat öyle pata küte değişikliklere başlamak yine başımıza bela olabilir. Gardımızı asla düşürmemek gerek. Değişikliğimizle birlikte davranışımızda değişiklik olacak mı, yoksa sadece kod üzerinde refactoring veya optimizing mı yapacağız? Buna vereceğiniz cevabın sonu, yine teste çıkacaktır.
Kodumuzun davranışına yeni bir feature gelecekse ve yahut var olan davranış değişecekse bunun için tekrardan test yazmanız gerekecektir. Bu konuda, TDD(Test Driven Development) uygulamak daha defensive bir yaklaşım olacaktır.
Ve son olarak, as-is yapıda refactoring veya optimizing yapılacaksa kodumuzun davranışında değişiklik olmamasını isteriz. Bu nedenle şu ana kadar yazdığımız testler bizleri korumaya devam edecektir. Eğer ki refactorümüz sonunda testlerimizden birisini patlamış olarak görürsek bir şeyleri yanlış yapmışız demektir.
Legacy kodlarla çalışmak bazen stresli ve yorucu olabilir, ancak doğru teknikleri uyguladığında süreci daha yönetilebilir hale getirmek yine bizim elimizde. Test yazmadan yapılan değişikliklerin ne kadar riskli olabileceğini gördük ve testlerin yalnızca bir güvenlik ağı değil, aynı zamanda en iyi dokümantasyon aracı olduğunu tekrardan hatırladık. Burada projelere belki kötü düyerek haksızlık etmiş de olabilirim. Her kötü kod parçası sonuçta bir zamanlar bir geliştiricinin en iyi çözümüydü – belki de ileride bizlerin de yazdığı kod, bir başkasının legacy kodu olacak. Bu bilinçle kod yazacağımızı umuyor, sağlıcakla kalmanızı diliyorum.